Advanced scheduling using affinity and anti-affinity rules
This blog post shows how KubeVirt can take advantage of Kubernetes inner features to provide an advanced scheduling mechanism to virtual machines (VMs). The same or even more complex affinity and anti-affinity rules can be assigned to VMs or Pods in Kubernetes than in traditional virtualization solutions.
It is important to notice that from the Kubernetes scheduler stand point, which will be explained later, it only manages Pod and node scheduling. Since the VM is wrapped up in a Pod, the same scheduling rules are completely valid to KubeVirt VMs.
Warning
As informed in the official Kubernetes documentation: inter-pod affinity and anti-affinity require substantial amount of processing which can slow-down scheduling in large clusters significantly. This can be specially notorious in clusters larger than several hundred nodes.
Introduction
In a Kubernetes cluster, kube-scheduler is the default scheduler and runs as part of the control plane. Kube-scheduler is in charge of selecting an optimal node for every newly created or unscheduled pod to run on. However, every container within a pod and the pods themselves, have different requirements for resources. Therefore, existing nodes need to be filtered according to the specific requirements.
Note
If you want and need to, you can write your own scheduling component and use it instead.
When we talk about scheduling, we refer basically to making sure that Pods are matched to Nodes so that a Kubelet can run them. Actually, kube-scheduler selects a node for the pod in a 2-step operation:
- Filtering. The filtering step finds the set of candidate Nodes where it’s possible to schedule the Pod. The result is a list of Nodes, usually more than one.
- Scoring. In the scoring step, the scheduler ranks the remaining nodes to choose the most suitable Pod placement. This is accomplished based on a score obtained from a list of scoring rules that are applied by the scheduler.
The obtained list of candidate nodes is evaluated using multiple priority criteria, which add up to a weighted score. Nodes with higher values are better candidates to run the pod. Among the criteria are affinity and anti-affinity rules; nodes with higher affinity for the pod have a higher score, and nodes with higher anti-affinity have a lower score. Finally, kube-scheduler assigns the Pod to the Node with the highest score. If there is more than one node with equal scores, kube-scheduler selects one of these randomly.
In this blog post we are going to focus on examples of affinity and anti-affinity rules applied to solve real use cases. A common use for affinity rules is to schedule related pods to be close to each other for performance reasons. A common use case for anti-affinity rules is to schedule related pods not too close to each other for high availability reasons.
Goal: Run my customapp
In this example, our mission is to run a customapp that is composed of 3 tiers:
- A web proxy cache based on varnish HTTP cache.
- A web appliance delivered by a third provider.
- A clustered database running on MS Windows.
Instructions were delivered to deploy the application in our production Kubernetes cluster taking advantage of the existing KubeVirt integration and making sure the application is resilient to any problems that can occur. The current status of the cluster is the following:
- A stretched Kubernetes cluster is already up and running.
- KubeVirt is already installed.
- There is enough free CPU, Memory and disk space in the cluster to deploy customapp stack.
information
The Kubernetes stretched cluster is running in 3 different geographical locations to provide high availability. Also, all locations are close and well-connected to provide low latency between the nodes.
Topology used is common for large data centers, such as cloud providers, which is based in organizing hosts into regions and zones:
- A region is a set of hosts in a close geographic area, which guarantees high-speed connectivity between them.
- A zone, also called an availability zone, is a set of hosts that might fail together because they share common critical infrastructure components, such as a network, storage, or power.
There are some important labels when creating advanced scheduling workflows with affinity and anti-affinity rules. As explained previously, they are very close linked to common topologies used in datacenters. Labels such as:
- topology.kubernetes.io/zone
- topology.kubernetes.io/region
- kubernetes.io/hostname
- kubernetes.io/arch
- kubernetes.io/os
Warning
As it is detailed in the labels and annotations official documentation, starting in v1.17, label failure-domain.beta.kubernetes.io/region and failure-domain.beta.kubernetes.io/zone are deprecated in favour of topology.kubernetes.io/region and topology kubernetes.io/zone respectively.
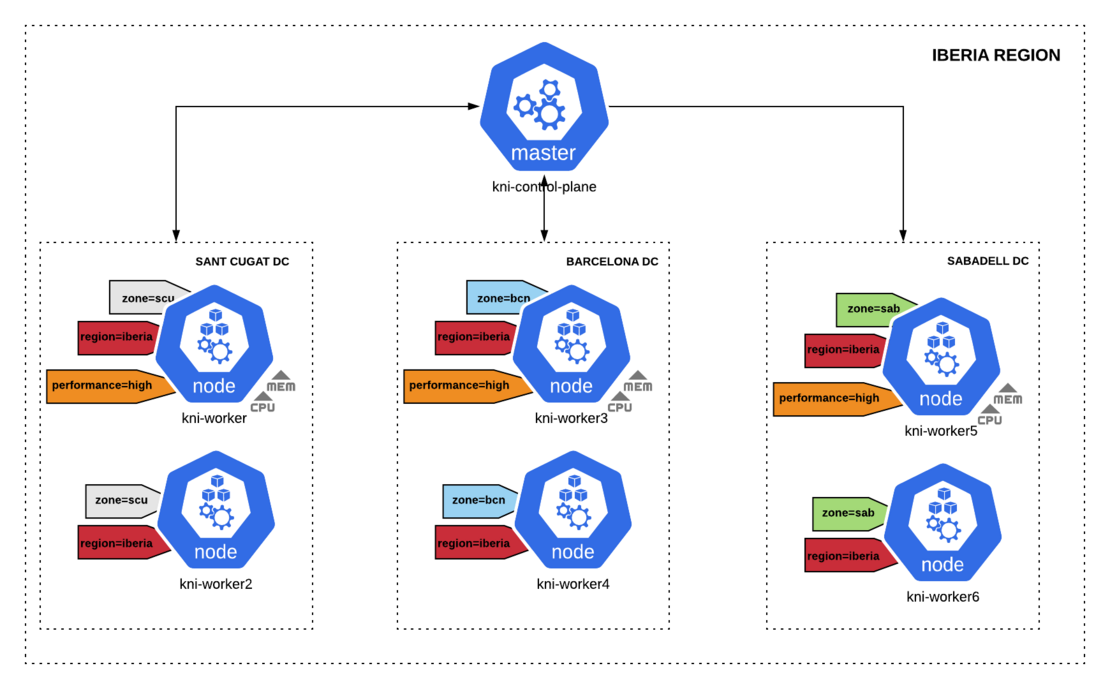
Previous labels are just prepopulated Kubernetes labels that the system uses to denote such a topology domain. In our case, the cluster is running in Iberia region across three different zones: scu, bcn and sab. Therefore, it must be labelled accordingly since advanced scheduling rules are going to be applied:
Information
Pod anti-affinity requires nodes to be consistently labelled, i.e. every node in the cluster must have an appropriate label matching topologyKey. If some or all nodes are missing the specified topologyKey label, it can lead to unintended behavior.
Below you can find a cluster labeling where topology is based in one region and several zones spread across geographically. Additionally, special high performing nodes composed by nodes with a high number of resources available including memory, cpu, storage and network are marked as well.
$ kubectl label node kni-worker topology.kubernetes.io/region=iberia topology.kubernetes.io/zone=scu
node/kni-worker labeled
$ kubectl label node kni-worker2 topology.kubernetes.io/region=iberia topology.kubernetes.io/zone=scu performance=high
node/kni-worker2 labeled
$ kubectl label node kni-worker3 topology.kubernetes.io/region=iberia topology.kubernetes.io/zone=bcn
node/kni-worker3 labeled
$ kubectl label node kni-worker4 topology.kubernetes.io/region=iberia topology.kubernetes.io/zone=bcn performance=high
node/kni-worker4 labeled
$ kubectl label node kni-worker5 topology.kubernetes.io/region=iberia topology.kubernetes.io/zone=sab
node/kni-worker5 labeled
$ kubectl label node kni-worker6 topology.kubernetes.io/region=iberia topology.kubernetes.io/zone=sab performance=high
node/kni-worker6 labeled
At this point, Kubernetes cluster nodes are labelled as expected:
$ kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
kni-control-plane Ready master 18m v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kni-control-plane,kubernetes.io/os=linux,node-role.kubernetes.io/master=
kni-worker Ready <none> 17m v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kni-worker,kubernetes.io/os=linux,topology.kubernetes.io/region=iberia,topology.kubernetes.io/zone=scu
kni-worker2 Ready <none> 17m v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kni-worker2,kubernetes.io/os=linux,performance=high,topology.kubernetes.io/region=iberia,topology.kubernetes.io/zone=scu
kni-worker3 Ready <none> 17m v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kni-worker3,kubernetes.io/os=linux,topology.kubernetes.io/region=iberia,topology.kubernetes.io/zone=bcn
kni-worker4 Ready <none> 17m v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kni-worker4,kubernetes.io/os=linux,performance=high,topology.kubernetes.io/region=iberia,topology.kubernetes.io/zone=bcn
kni-worker5 Ready <none> 17m v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kni-worker5,kubernetes.io/os=linux,topology.kubernetes.io/region=iberia,topology.kubernetes.io/zone=sab
kni-worker6 Ready <none> 17m v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kni-worker6,kubernetes.io/os=linux,performance=high,topology.kubernetes.io/region=iberia,topology.kubernetes.io/zone=sab
Finally, the cluster is ready to run and deploy our specific customapp.
The clustered database
A MS Windows 2016 Server virtual machine is already containerized and ready to be deployed. As we have to deploy 3 replicas of the operating system a VirtualMachineInstanceReplicaSet has been created. Once the replicas are up and running, database administrators will be able to reach the VMs running in our Kubernetes cluster through Remote Desktop Protocol (RDP). Eventually, MS SQL2016 database is installed and configured as a clustered database to provide high availability to our customapp.
Information
Check KubeVirt: installing Microsoft Windows from an ISO if you need further information on how to deploy a MS Windows VM on KubeVirt.
Regarding the scheduling, a Kubernetes node of each zone has been labelled as high-performance, e.g. it has more memory, storage, CPU and higher performing disk and network than the other node that shares the same zone. This specific Kubernetes node was provisioned to run the database VM due to the hardware requirements to run database applications. Therefore, a scheduling rule is needed to be sure that all MSSQL2016 instances run only in these high-performance servers.
Note
These nodes were labelled as performance=high.
There are two options to accomplish our requirement, use nodeSelector or configure nodeAffinity rules. In our first approach, nodeSelector instead of nodeAffinity rule is used. nodeSelector matches the nodes where the performance key is equal to high and makes the VirtualMachineInstance to run on top of the matching nodes. The following code snippet shows the configuration:
apiVersion: kubevirt.io/v1alpha3
kind: VirtualMachineInstanceReplicaSet
metadata:
name: mssql2016
spec:
replicas: 3
selector:
matchLabels:
kubevirt.io/domain: mssql2016
template:
metadata:
name: mssql2016
labels:
kubevirt.io/domain: mssql2016
spec:
nodeSelector: #nodeSelector matches nodes where performance key has high as value.
performance: high
domain:
devices:
disks:
- disk:
bus: virtio
name: containerdisk
- disk:
bus: virtio
name: cloudinitdisk
interfaces:
- bridge: {}
name: default
machine:
type: ""
resources:
requests:
memory: 16Gi
networks:
- name: default
pod: {}
Next, the VirtualMachineInstanceReplicaSet configuration partially shown previously is applied successfully.
$ kubectl create -f vmr-windows-mssql.yaml
virtualmachineinstancereplicaset.kubevirt.io/mssql2016 created
Then, it is expected that the 3 VirtualMachineInstances will eventually run on the nodes where matching key/value label is configured. Actually, based on the hostname those are the even nodes.
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
virt-launcher-mssql2016p948r-257pn 0/2 ContainerCreating 0 16s <none> kni-worker4 <none> <none>
virt-launcher-mssql2016rd4lk-6zz9d 0/2 ContainerCreating 0 16s <none> kni-worker2 <none> <none>
virt-launcher-mssql2016z2qnw-t924b 0/2 ContainerCreating 0 16s <none> kni-worker6 <none> <none>
[root@eko1 ind-affinity]# kubectl get vmi -o wide
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
mssql2016p948r 34s Scheduling
mssql2016rd4lk 34s Scheduling
mssql2016z2qnw 34s Scheduling
$ kubectl get vmi -o wide
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
mssql2016p948r 3m25s Running 10.244.1.4 kni-worker4 False
mssql2016rd4lk 3m25s Running 10.244.2.4 kni-worker2 False
mssql2016z2qnw 3m25s Running 10.244.5.4 kni-worker6 False
Warning
nodeSelector provides a very simple way to constrain pods to nodes with particular labels. The affinity/anti-affinity feature greatly expands the types of constraints you can express.
Let’s test what happens if the node running the database must be rebooted due to an upgrade or any other valid reason. First, a node drain must be executed in order to evacuate all pods running and mark the node as unschedulable.
$ kubectl drain kni-worker2 --delete-local-data --ignore-daemonsets=true --force
node/kni-worker2 already cordoned
evicting pod "virt-launcher-mssql2016rd4lk-6zz9d"
pod/virt-launcher-mssql2016rd4lk-6zz9d evicted
node/kni-worker2 evicted
The result is an unwanted scenario, where two databases are being executed in the same high performing server. This leads us to more advanced scheduling features like affinity and anti-affinity.
$ kubectl get vmi -o wide
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
mssql201696sz9 7m16s Running 10.244.5.5 kni-worker6 False
mssql2016p948r 19m Running 10.244.1.4 kni-worker4 False
mssql2016z2qnw 19m Running 10.244.5.4 kni-worker6 False
The affinity/anti-affinity rules solve much more complex scenarios compared to nodeSelector. Some of the key enhancements are:
- The language is more expressive (not just “AND or exact match”).
- You can indicate that the rule is “soft”/”preference” rather than a hard requirement, so if the scheduler can’t satisfy it, the pod will still be scheduled.
- You can constrain against labels on other pods running on the node (or other topological domain), rather than against labels on the node itself, which allows rules about which pods can and cannot be co-located.
Before going into more detail, it should be noticed that there are currently two types of affinity that applies to both Node and Pod affinity. They are called requiredDuringSchedulingIgnoredDuringExecution and preferredDuringSchedulingIgnoredDuringExecution. You can think of them as hard and soft respectively, in the sense that the former specifies rules that must be met for a pod to be scheduled onto a node (just like nodeSelector but using a more expressive syntax), while the latter specifies preferences that the scheduler will try to enforce but will not guarantee.
Said that, it is time to edit the VirtualMachineInstanceReplicaSet YAML file. Actually, nodeSelector must be removed and two different affinity rules created instead.
- nodeAffinity rule. This rule ensures that during scheduling time the application (MS SQL2016) must be placed only on nodes where the key performance contains the value high. Note the word only, there is no room for other nodes.
- podAntiAffinity rule. This rule ensures that two applications with the key
kubevirt.io/domainequals tomssql2016must not run in the same zone. Notice that the only application with this key value is the database itself and more important, notice that this rule applies to the topologyKeytopology.kubernetes.io/zone. This means that only one database instance can run in each zone, e.g. one database in scu, bcn and sab respectively.
In principle, the topologyKey can be any legal label-key. However, for performance and security reasons, there are some constraints on topologyKey that need to be taken into consideration:
- For affinity and for
requiredDuringSchedulingIgnoredDuringExecutionpod anti-affinity, emptytopologyKeyis not allowed. - For
preferredDuringSchedulingIgnoredDuringExecutionpod anti-affinity, emptytopologyKeyis interpreted as “all topologies” (“all topologies” here is now limited to the combination ofkubernetes.io/hostname,topology.kubernetes.io/zoneandtopology.kubernetes.io/region). - For
requiredDuringSchedulingIgnoredDuringExecutionpod anti-affinity, the admission controllerLimitPodHardAntiAffinityTopologywas introduced to limittopologyKeytokubernetes.io/hostname. Verify if it is enabled or disabled.
Here is the VirtualMachineInstanceReplicaSet object replaced.
$ kubectl edit virtualmachineinstancereplicaset.kubevirt.io/mssql2016
virtualmachineinstancereplicaset.kubevirt.io/mssql2016 edited
Now, it contains both affinity rules:
apiVersion: kubevirt.io/v1alpha3
kind: VirtualMachineInstanceReplicaSet
metadata:
name: mssql2016replicaset
spec:
replicas: 3
selector:
matchLabels:
kubevirt.io/domain: mssql2016
template:
metadata:
name: mssql2016
labels:
kubevirt.io/domain: mssql2016
spec:
affinity:
nodeAffinity: #This rule ensures the application (MS SQL2016) must ONLY be placed on nodes where the key performance contains the value high
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: performance
operator: In
values:
- high
podAntiAffinity: #This rule ensures that two applications with the key kubevirt.io/domain equals to mssql2016 cannot run in the same zone
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: kubevirt.io/domain
operator: In
values:
- mssql2016
topologyKey: topology.kubernetes.io/zone
domain:
Notice that the VM or POD placement is executed only during the scheduling process, therefore we need to delete one of the VirtualMachineInstances (VMI) running in the same node. Deleting the VMI will make Kubernetes spin up a new one to reconcile the desired number of replicas (3).
Information
Remember to mark the kni-worker2 as schedulable again.
$ kubectl uncordon kni-worker2
node/kni-worker2 uncordoned
Below shows the current status, where two databases are running in the kni-worker6 node. By applying the previous affinity rules this should not happen again:
$ kubectl get vmi -o wide
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
mssql201696sz9 12m Running 10.244.5.5 kni-worker6 False
mssql2016p948r 24m Running 10.244.1.4 kni-worker4 False
mssql2016z2qnw 24m Running 10.244.5.4 kni-worker6 False
Next, we delete one of the VMIs running in kni-worker6 and wait for the rules to be applied at scheduling time. As can be seen, databases are distributed across zones and high performing nodes:
$ kubectl delete vmi mssql201696sz9
virtualmachineinstance.kubevirt.io "mssql201696sz9" deleted
$ kubectl get vmi -o wide
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
mssql2016p948r 40m Running 10.244.1.4 kni-worker4 False
mssql2016tpj6n 22s Running 10.244.2.5 kni-worker2 False
mssql2016z2qnw 40m Running 10.244.5.4 kni-worker6 False
During the deployment of the clustered database nodeAffinity and nodeSelector rules were compared, however, there are a couple of things to take into consideration when creating node affinity rules, it is worth taking a look at node affinity in Kubernetes documentation.
Information
If you remove or change the label of the node where the Pod is scheduled, the Pod will not be removed. In other words, the affinity selection works only at the time of scheduling the Pod.
The proxy http cache
Now, that the database is configured by database administrators and running across multiple zones, it’s time to spin up the varnish http-cache container image. This time we are going to run it as a Pod instead of as a KubeVirt VM., however, scheduling rules are still valid for both objects.
A detailed explanation on how to run a Varnish Cache in a Kubernetes cluster can be found in kube-httpcache repository. Below are detailed the steps taken:
Start by creating a ConfigMap that contains a VCL template and a Secret object that contains the secret for the Varnish administration port. Then apply the Varnish deployment config.
$ kubectl create -f configmap.yaml
configmap/vcl-template created
$ kubectl create secret generic varnish-secret --from-literal=secret=$(head -c32 /dev/urandom | base64)
secret/varnish-secret created
In our specific mandate, 3 replicas of our web cache application are needed. Each one must be running in a different zone or datacenter. Preferably, if possible, expected to run in a Kubernetes node different from the database since as administrators we would like the database to take advantage of all the possible resources of the high-performing server. Taken into account this prerequisite, the following advanced rules are applied:
- nodeAffinity rule. This rule ensures that during scheduling time the application should be placed if possible on nodes where the key performance does not contain the value high. Note the word if possible. This means, it will try to run on a not performing server, however, if there none available it will be co-located with the database.
- podAntiAffinity rule. This rule ensures that two applications with the key
appequals tocachemust not run in the same zone. Notice that the only application with this key value is the Varnish http-cache itself and more important, notice that this rule applies to the topologyKeytopology.kubernetes.io/zone. This means that only one Varnish http-cache instance can run in each zone, e.g. one http-cache in scu, bcn and sab respectively.
apiVersion: apps/v1
kind: Deployment
metadata:
name: varnish-cache
spec:
selector:
matchLabels:
app: cache
replicas: 3
template:
metadata:
labels:
app: cache
spec:
affinity:
nodeAffinity: #This rule ensures that during scheduling time the application must be placed *if possible* on nodes NOT performance=high
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: performance
operator: NotIn
values:
- high
podAntiAffinity: #This rule ensures that the application cannot run in the same zone (app=cache).
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- cache
topologyKey: topology.kubernetes.io/zone
containers:
- name: cache
image: quay.io/spaces/kube-httpcache:stable
imagePullPolicy: Always
Information
In this set of affinity rules, a new scheduling policy has been introduced: preferredDuringSchedulingIgnoredDuringExecution. It can be thought as “soft” scheduling, in the sense that it specifies preferences that the scheduler will try to enforce but will not guarantee.
The weight field in preferredDuringSchedulingIgnoredDuringExecution must be in the range 1-100 and it is taken into account in the scoring step. Remember that the node(s) with the highest total score is/are the most preferred.
Here, the modified deployment is applied:
[root@eko1 varnish]# kubectl create -f deployment.yaml
deployment.apps/varnish-cache created
The Pod is scheduled as expected since there is a node available in each zone without the performance=high label.
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
varnish-cache-54489f9fc9-5pbr2 1/1 Running 0 91s 10.244.4.5 kni-worker5 <none> <none>
varnish-cache-54489f9fc9-9s9tm 1/1 Running 0 91s 10.244.3.5 kni-worker3 <none> <none>
varnish-cache-54489f9fc9-dflzs 1/1 Running 0 91s 10.244.6.5 kni-worker <none> <none>
virt-launcher-mssql2016p948r-257pn 2/2 Running 0 70m 10.244.1.4 kni-worker4 <none> <none>
virt-launcher-mssql2016tpj6n-l2fnf 2/2 Running 0 31m 10.244.2.5 kni-worker2 <none> <none>
virt-launcher-mssql2016z2qnw-t924b 2/2 Running 0 70m 10.244.5.4 kni-worker6 <none> <none>
At this point, database and http-cache components of our customapp are up and running. Only the appliance created by an external provider needs to be deployed to complete the stack.
The third-party appliance virtual machine
A third-party provider delivered a black box (appliance) in the form of a virtual machine where the application bought by the finance department is installed. Lucky to us, we have been able to transform it into a container VM ready to be run in our cluster with the help of KubeVirt.
Following up with our objective, this web application must take advantage of the web cache application running as a Pod. So we require the appliance to be co-located in the same server that Varnish Cache in order to accelerate the delivery of the content provided by the appliance. Also, it is required to run every replica of the appliance in different zones or data centers. Taken into account these prerequisites, the following advanced rules are configured:
- podAffinity rule. This rule ensures that during scheduling time the application must be placed on nodes where an application (Pod) with key
app' equals tocache` is running. That is to say where the Varnish Cache is running. Note that this is mandatory, it will only run co-located with the web cache Pod. - podAntiAffinity rule. This rule ensures that two applications with the key
kubevirt.io/domainequals toblackboxmust not run in the same zone. Notice that the only application with this key value is the appliance and more important, notice that this rule applies to the topologyKeytopology.kubernetes.io/zone. This means that only one appliance instance can run in each zone, e.g. one appliance in scu, bcn and sab respectively.
apiVersion: kubevirt.io/v1alpha3
kind: VirtualMachineInstanceReplicaSet
metadata:
name: blackbox
spec:
replicas: 3
selector:
matchLabels:
kubevirt.io/domain: blackbox
template:
metadata:
name: blackbox
labels:
kubevirt.io/domain: blackbox
spec:
affinity:
podAffinity: #This rule ensures that during scheduling time the application must be placed on nodes where Varnish Cache is running
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- cache
topologyKey: topology.kubernetes.io/hostname
podAntiAffinity: #This rule ensures that two applications with the key `kubevirt.io/domain` equals to `blackbox` cannot run in the same zone
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "kubevirt.io/domain"
operator: In
values:
- blackbox
topologyKey: topology.kubernetes.io/zone
domain:
Here, the modified deployment is applied. As expected the VMI is scheduled as expected in the same Kubernetes nodes as Varnish Cache and each one in a different datacenter or zone.
$ kubectl get pods,vmi -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/varnish-cache-54489f9fc9-5pbr2 1/1 Running 0 172m 10.244.4.5 kni-worker5 <none> <none>
pod/varnish-cache-54489f9fc9-9s9tm 1/1 Running 0 172m 10.244.3.5 kni-worker3 <none> <none>
pod/varnish-cache-54489f9fc9-dflzs 1/1 Running 0 172m 10.244.6.5 kni-worker <none> <none>
pod/virt-launcher-blackboxtk49x-nw45s 2/2 Running 0 2m31s 10.244.6.6 kni-worker <none> <none>
pod/virt-launcher-blackboxxt829-snjth 2/2 Running 0 2m31s 10.244.4.9 kni-worker5 <none> <none>
pod/virt-launcher-blackboxzf9kt-6mh56 2/2 Running 0 2m31s 10.244.3.6 kni-worker3 <none> <none>
pod/virt-launcher-mssql2016p948r-257pn 2/2 Running 0 4h1m 10.244.1.4 kni-worker4 <none> <none>
pod/virt-launcher-mssql2016tpj6n-l2fnf 2/2 Running 0 3h22m 10.244.2.5 kni-worker2 <none> <none>
pod/virt-launcher-mssql2016z2qnw-t924b 2/2 Running 0 4h1m 10.244.5.4 kni-worker6 <none> <none>
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
virtualmachineinstance.kubevirt.io/blackboxtk49x 2m31s Running 10.244.6.6 kni-worker False
virtualmachineinstance.kubevirt.io/blackboxxt829 2m31s Running 10.244.4.9 kni-worker5 False
virtualmachineinstance.kubevirt.io/blackboxzf9kt 2m31s Running 10.244.3.6 kni-worker3 False
virtualmachineinstance.kubevirt.io/mssql2016p948r 4h1m Running 10.244.1.4 kni-worker4 False
virtualmachineinstance.kubevirt.io/mssql2016tpj6n 3h22m Running 10.244.2.5 kni-worker2 False
virtualmachineinstance.kubevirt.io/mssql2016z2qnw 4h1m Running 10.244.5.4 kni-worker6 False
At this point, our stack has been successfully deployed and configured accordingly to the requirements agreed. However, it is important before going into production to verify the proper behaviour in case of node failures. That’s what is going to be shown in the next section.
Verify the resiliency of our customapp
In this section, several tests must be executed to validate that the scheduling already in place is line up with the expected behaviour of the customapp application.
Draining a regular node
In this test, the node located in scu zone which is not labelled as high-performance will be upgraded. The proper procedure to maintain a Kubernetes node is as follows: drain the node, upgrade packages and then reboot it.
As it is depicted, once the kni-worker is marked as unschedulable and drained, the Varnish Cache pod and the black box appliance VM are automatically moved to the high-performance node in the same zone.
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/varnish-cache-54489f9fc9-5pbr2 1/1 Running 0 3h8m 10.244.4.5 kni-worker5 <none> <none>
pod/varnish-cache-54489f9fc9-9s5sr 1/1 Running 0 2m32s 10.244.2.7 kni-worker2 <none> <none>
pod/varnish-cache-54489f9fc9-9s9tm 1/1 Running 0 3h8m 10.244.3.5 kni-worker3 <none> <none>
pod/virt-launcher-blackboxxh5tg-g7hns 2/2 Running 0 13m 10.244.2.8 kni-worker2 <none> <none>
pod/virt-launcher-blackboxxt829-snjth 2/2 Running 0 18m 10.244.4.9 kni-worker5 <none> <none>
pod/virt-launcher-blackboxzf9kt-6mh56 2/2 Running 0 18m 10.244.3.6 kni-worker3 <none> <none>
pod/virt-launcher-mssql2016p948r-257pn 2/2 Running 0 4h17m 10.244.1.4 kni-worker4 <none> <none>
pod/virt-launcher-mssql2016tpj6n-l2fnf 2/2 Running 0 3h37m 10.244.2.5 kni-worker2 <none> <none>
pod/virt-launcher-mssql2016z2qnw-t924b 2/2 Running 0 4h17m 10.244.5.4 kni-worker6 <none> <none>
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
virtualmachineinstance.kubevirt.io/blackboxxh5tg 13m Running 10.244.2.8 kni-worker2 False
virtualmachineinstance.kubevirt.io/blackboxxt829 18m Running 10.244.4.9 kni-worker5 False
virtualmachineinstance.kubevirt.io/blackboxzf9kt 18m Running 10.244.3.6 kni-worker3 False
virtualmachineinstance.kubevirt.io/mssql2016p948r 4h17m Running 10.244.1.4 kni-worker4 False
virtualmachineinstance.kubevirt.io/mssql2016tpj6n 3h37m Running 10.244.2.5 kni-worker2 False
virtualmachineinstance.kubevirt.io/mssql2016z2qnw 4h17m Running 10.244.5.4 kni-worker6 False
Remember that this is happening because:
- There is a mandatory policy that only one replica of each application can run at the same time in the same zone.
- There is a soft policy (preferred) that both applications should run on a non high-performance node. However, since there are any of these nodes available it has been scheduled in the high-performance server along with the database.
- Both applications must run in the same node
Information
Note that uncordoning the node will not make the blackbox appliance and the Varnish Cache pod to come back to the previous node.
$ kubectl uncordon kni-worker
node/kni-worker uncordoned
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/varnish-cache-54489f9fc9-5pbr2 1/1 Running 0 3h10m 10.244.4.5 kni-worker5 <none> <none>
pod/varnish-cache-54489f9fc9-9s5sr 1/1 Running 0 5m29s 10.244.2.7 kni-worker2 <none> <none>
pod/varnish-cache-54489f9fc9-9s9tm 1/1 Running 0 3h10m 10.244.3.5 kni-worker3 <none> <none>
pod/virt-launcher-blackboxxh5tg-g7hns 2/2 Running 0 16m 10.244.2.8 kni-worker2 <none> <none>
pod/virt-launcher-blackboxxt829-snjth 2/2 Running 0 21m 10.244.4.9 kni-worker5 <none> <none>
pod/virt-launcher-blackboxzf9kt-6mh56 2/2 Running 0 21m 10.244.3.6 kni-worker3 <none> <none>
pod/virt-launcher-mssql2016p948r-257pn 2/2 Running 0 4h20m 10.244.1.4 kni-worker4 <none> <none>
pod/virt-launcher-mssql2016tpj6n-l2fnf 2/2 Running 0 3h40m 10.244.2.5 kni-worker2 <none> <none>
pod/virt-launcher-mssql2016z2qnw-t924b 2/2 Running 0 4h20m 10.244.5.4 kni-worker6 <none> <none>
In order to return to the most desirable state, the pod and VM from kni-worker2 must be deleted.
Information
Both applications must be deleted since the requiredDuringSchedulingIgnoredDuringExecution policy is only applied during scheduling time.
$ kubectl delete pod/varnish-cache-54489f9fc9-9s5sr
pod "varnish-cache-54489f9fc9-9s5sr" deleted
$ kubectl delete virtualmachineinstance.kubevirt.io/blackboxxh5tg
virtualmachineinstance.kubevirt.io "blackboxxh5tg" deleted
Once done, the scheduling process is run again for both applications and the applications are placed in the most desirable node taking into account affinity rules configured.
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/varnish-cache-54489f9fc9-5pbr2 1/1 Running 0 3h13m 10.244.4.5 kni-worker5 <none> <none>
pod/varnish-cache-54489f9fc9-9s9tm 1/1 Running 0 3h13m 10.244.3.5 kni-worker3 <none> <none>
pod/varnish-cache-54489f9fc9-fldhc 1/1 Running 0 2m7s 10.244.6.7 kni-worker <none> <none>
pod/virt-launcher-blackbox54l7t-4c6wh 2/2 Running 0 23s 10.244.6.8 kni-worker <none> <none>
pod/virt-launcher-blackboxxt829-snjth 2/2 Running 0 23m 10.244.4.9 kni-worker5 <none> <none>
pod/virt-launcher-blackboxzf9kt-6mh56 2/2 Running 0 23m 10.244.3.6 kni-worker3 <none> <none>
pod/virt-launcher-mssql2016p948r-257pn 2/2 Running 0 4h23m 10.244.1.4 kni-worker4 <none> <none>
pod/virt-launcher-mssql2016tpj6n-l2fnf 2/2 Running 0 3h43m 10.244.2.5 kni-worker2 <none> <none>
pod/virt-launcher-mssql2016z2qnw-t924b 2/2 Running 0 4h23m 10.244.5.4 kni-worker6 <none> <none>
NAME AGE PHASE IP NODENAME LIVE-MIGRATABLE
virtualmachineinstance.kubevirt.io/blackbox54l7t 23s Running 10.244.6.8 kni-worker False
virtualmachineinstance.kubevirt.io/blackboxxt829 23m Running 10.244.4.9 kni-worker5 False
virtualmachineinstance.kubevirt.io/blackboxzf9kt 23m Running 10.244.3.6 kni-worker3 False
virtualmachineinstance.kubevirt.io/mssql2016p948r 4h23m Running 10.244.1.4 kni-worker4 False
virtualmachineinstance.kubevirt.io/mssql2016tpj6n 3h43m Running 10.244.2.5 kni-worker2 False
virtualmachineinstance.kubevirt.io/mssql2016z2qnw 4h23m Running 10.244.5.4 kni-worker6 False
This behaviour can be extrapolated to a failure or shutdown of any odd or non high-performance worker node. In that case, all workloads will be moved to the high performing server in the same zone. Although this is not ideal, our customapp will be still available while the node recovery is ongoing.
Draining a high-performance node
On the other hand, in case of a high-performance worker node failure, which was shown previously, the database will not be able to move to another server, since there is only one high performing server per zone. A possible solution is just adding a stand-by high-performance node in each zone.
However, since the database is configured as a clustered database, the application running in the same zone as the failed database will still be able to establish a connection to any of the other two running databases located in different zones. This configuration is done at the application level. Actually, from the application standpoint, it just connects to a database pool of resources.
Since this is not ideal either, e.g. establishing a connection to another zone or datacenter takes longer than in the same datacenter, the application will be still available and providing service to the clients.
Affinity rules are everywhere
As written in the title section, affinity rules are essential to provide high availability and resiliency to Kubernetes applications. Furthermore, KubeVirt’s components also take advantage of these rules to avoid unwanted situations that could compromise the stability of the VMs running in the cluster.
For instance, below it is partly shown a snippet of the deployment object for virt-api and virt-controller. Notice the following affinity rule created:
- podAntiAffinity rule. This rule ensures that two replicas of the same application should not run if possible in the same Kubernetes node (
kubernetes.io/hostname). It is used the keykubevirt.ioto match the applicationvirt-apiorvirt-controller. See that it is a soft requirement, which means that the kube-scheduler will try to match the rule, however, if it is not possible it can place both replicas in the same node.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
kubevirt.io: virt-api
name: virt-api
namespace: kubevirt
spec:
replicas: 2
selector:
matchLabels:
kubevirt.io: virt-api
strategy: {}
template:
metadata:
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
scheduler.alpha.kubernetes.io/tolerations: '[{"key":"CriticalAddonsOnly","operator":"Exists"}]'
labels:
kubevirt.io: virt-api
prometheus.kubevirt.io: ""
name: virt-api
spec:
affinity:
podAntiAffinity: #This rule ensures that two replicas of the same application should not run if possible in the same Kubernetes node
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: kubevirt.io
operator: In
values:
- virt-api
topologyKey: kubernetes.io/hostname
weight: 1
containers:
...
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
kubevirt.io: virt-controller
name: virt-controller
namespace: kubevirt
spec:
replicas: 2
selector:
matchLabels:
kubevirt.io: virt-controller
strategy: {}
template:
metadata:
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
scheduler.alpha.kubernetes.io/tolerations: '[{"key":"CriticalAddonsOnly","operator":"Exists"}]'
labels:
kubevirt.io: virt-controller
prometheus.kubevirt.io: ""
name: virt-controller
spec:
affinity:
podAntiAffinity: #This rule ensures that two replicas of the same application should not run if possible in the same Kubernetes node
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: kubevirt.io
operator: In
values:
- virt-controller
topologyKey: kubernetes.io/hostname
weight: 1
Information
It is worth mentioning that DaemonSets internally also uses advanced scheduling rules. Basically, they are nodeAffinity rules in order to place each replica in each Kubernetes node of the cluster.
A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
[root@eko1 varnish]# kubectl get daemonset -n kubevirt
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kubevirt virt-handler 6 6 6 6 6 <none> 25h
See the partial snippet of a virt-handler Pod created by a DaemonSet (see ownerReferences section, kind: DaemonSet) that configures a nodeAffinity rule that requires the Pod to run in a specific hostname matched by the key metadata.name and value the name of the node (kni-worker2). Note that the value of the key changes depending on the nodes that are part of the cluster, this is done by the DaemonSet.
apiVersion: v1
kind: Pod
metadata:
annotations:
kubevirt.io/install-strategy-identifier: 0000ee7f7cd4756bb221037885c3c86816db6de7
kubevirt.io/install-strategy-registry: index.docker.io/kubevirt
kubevirt.io/install-strategy-version: v0.26.0
scheduler.alpha.kubernetes.io/critical-pod: ""
scheduler.alpha.kubernetes.io/tolerations: '[{"key":"CriticalAddonsOnly","operator":"Exists"}]'
creationTimestamp: "2020-02-12T11:11:14Z"
generateName: virt-handler-
labels:
app.kubernetes.io/managed-by: kubevirt-operator
controller-revision-hash: 84d96d4775
kubevirt.io: virt-handler
pod-template-generation: "1"
prometheus.kubevirt.io: ""
name: virt-handler-ctzcg
namespace: kubevirt
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: DaemonSet
name: virt-handler
uid: 6e7faece-a7aa-4ed0-959e-4332b2be4ec3
resourceVersion: "28301"
selfLink: /api/v1/namespaces/kubevirt/pods/virt-handler-ctzcg
uid: 95d68dad-ad06-489f-b3d3-92413bcae1da
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- kni-worker2
Summary
In this blog post, a real use case has been detailed on how advanced scheduling can be configured in a hybrid scenario where VMs and Pods are part of the same application stack. The reader can realize that Kubernetes itself already provides a lot of functionality out of the box to Pods running on top of it. One of these inherited capabilities is the possibility to create even more complex affinity or/and anti-affinity rules than traditional virtualization products.